
Turning Hours of Gamer Rants into Searchable Gold with n8n and Supabase

Introduction
Besides writing about software architecture and tinkering with homelabs, I also run a podcast: GamerTV Podcast.
It’s a Spanish-language podcast about videogames, told from the perspective of two 40-something grumpy gamers — yours truly (Darth Seldon) and my co-host Mr. Chilangiux. We rant, reminisce, and sometimes even make sense of the gaming world.
But here’s the problem: podcasts are fantastic to listen to, yet impossible to search. When you want to find that one spicy rant about Final Fantasy VII remakes or a deep dive into retro emulation… good luck scrubbing through hours of audio.
That’s why we’re building this workflow: to automate transcription and storage of our episodes using n8n, so later we can layer on semantic search and finally make our content discoverable.
This post builds on our earlier article: Build Your Own Local AI Automation Hub with n8n + Ollama, where we created local Docker containers for n8n and Ollama. Now, we’ll extend that stack with Whisper ASR transcription and Supabase vector storage.
Why n8n?
If you’ve ever played with Zapier or IFTTT, you know automation tools can glue services together. n8n takes that to another level:
- Open source.
- Self-hosted with Docker.
- Extensible with dozens of nodes to connect APIs, databases, and services.
For this project, we’re using n8n nodes for:
- GitHub Node – fetches new audio files and commits transcripts.
- Airtable Node – logs progress, saves settings.
- HTTP Request Node – calls Whisper ASR and Ollama APIs.
- Function Node (JavaScript) – custom logic (checking file extensions, chunking transcripts).
- Supabase Node – stores transcripts and embeddings.
- File Node – handles
.mp3,.txt,.srtdata streams.
The real magic? You design the workflow visually, and n8n executes it step by step.
Setting up Whisper ASR with Docker Compose
We’ll use a lightweight Whisper ASR web service container. Add this to your docker-compose.yml alongside your existing n8n and Ollama containers:
services:
whisper-asr:
image: rhasspy/whisper-asr-webservice:latest
container_name: whisper-asr
ports:
- "9000:9000"
environment:
- ASR_MODEL=base
restart: unless-stopped
This exposes an HTTP API at http://host.docker.internal:9000/asr. n8n’s HTTP Request node can send .mp3 files and get back transcripts in .txt or .srt.
Example call from n8n:
POST http://host.docker.internal:9000/asr?task=transcribe&language=es&output=txt
But you can also use the openapi url
Using Ollama for Embeddings
From our previous post, we already have Ollama running in Docker. This time, instead of using it for chat, we’ll call the embedding API with the Llama3.1:8b model.
POST http://host.docker.internal:11434/api/embeddings
Content-Type: application/json
{
"model": "llama3.1:8b",
"input": "This is a transcript chunk."
}
Or you can use the n8n Supabase vector database and use the ollama embeddings. Note that you can use any type of embedding (OpenAI comes to mind) but will need to change the size of the chunks, more on that later.
These embeddings are stored in Supabase via the pgvector extension.
Airtable Setup
Airtable is our tracker and settings store:
- Settings Table: model names, thresholds, API keys.
- Episodes Table: episode ID, filename, language, processed flags.
- Progress Table: workflow runs, transcript/vectorization status.
n8n updates Airtable at every stage so we always know which episodes are ready.
Setting Airtable is so simple I won't bother to mention how to set it up, however if iIsee enough interest I will update the post.
Supabase Setup
Supabase is our storage backend. Create a new project and run this in the SQL editor:
-- Enable the pgvector extension to work with embedding vectors
create extension vector;
-- Create a table to store your documents
create table documents (
id bigserial primary key,
content text, -- corresponds to Document.pageContent
metadata jsonb, -- corresponds to Document.metadata
embedding vector(1536) -- 1536 works for OpenAI embeddings, change if needed
);
-- Create a function to search for documents
create function match_documents (
query_embedding vector(1536),
match_count int default null,
filter jsonb DEFAULT '{}'
) returns table (
id bigint,
content text,
metadata jsonb,
similarity float
)
language plpgsql
as $$
#variable_conflict use_column
begin
return query
select
id,
content,
metadata,
1 - (documents.embedding <=> query_embedding) as similarity
from documents
where metadata @> filter
order by documents.embedding <=> query_embedding
limit match_count;
end;
$$;This table will store transcripts as documents (documents), metadata (episodeId, timestamps, etc.), and embeddings.
As well a function to search over the documents.
Relational, Vector, and Node Databases
Since we’re mixing approaches, here’s a quick cheat sheet:
- Relational (Postgres, MySQL) → structured metadata and transcripts.
- Vector (pgvector, Pinecone) → semantic embeddings for similarity.
- Node/Graph (Neo4j) → relationships, like who appeared in which episodes.
Supabase with pgvector lets us combine relational and vector in one database.
{
"name": "Blog Automate Podcast",
"nodes": [
{
"parameters": {},
"type": "n8n-nodes-base.manualTrigger",
"typeVersion": 1,
"position": [
-3136,
576
],
"id": "7b4359e9-34cb-47c6-9394-ad3d08907ddf",
"name": "When clicking ‘Execute workflow’"
},
{
"parameters": {
"url": "https://api.github.com/repos/YOURUSER/YOURREPO/git/trees/main?recursive=1",
"sendHeaders": true,
"headerParameters": {
"parameters": [
{
"name": "Authorization",
"value": "token YOUR_TOKEN"
},
{
"name": "Accept",
"value": "application/vnd.github.v3+json"
}
]
},
"options": {}
},
"type": "n8n-nodes-base.httpRequest",
"typeVersion": 4.2,
"position": [
-2912,
576
],
"id": "1196554b-d28d-4204-b2f7-897c41684da7",
"name": "Obtain recursive git"
},
{
"parameters": {
"jsCode": "const allFiles = [];\nconst mediaFiles = [];\nconst companionFiles = new Map(); // Map to track TXT/SRT companions\nconst mediaCompanions = new Map(); // Map to track MP3/MP4 companions\n\n// Collect and categorize all files\nfor (const item of $input.all()) {\n const tree = item.json.tree;\n \n tree.forEach(file => {\n if (file.type === 'blob') {\n const filePath = file.path;\n const fileName = filePath.split('/').pop();\n const directory = filePath.substring(0, filePath.lastIndexOf('/'));\n const extension = fileName.toLowerCase().split('.').pop();\n const nameWithoutExt = fileName.substring(0, fileName.lastIndexOf('.'));\n \n const fileObj = {\n path: filePath,\n directory: directory,\n fileName: fileName,\n nameWithoutExt: nameWithoutExt,\n extension: extension,\n sha: file.sha,\n url: file.url,\n size: file.size\n };\n \n // Collect MP3\n if (extension === 'mp3') {\n mediaFiles.push(fileObj);\n \n // Track media companions (MP3/MP4 pairs)\n const baseKey = `${directory}/${nameWithoutExt}`;\n if (!mediaCompanions.has(baseKey)) {\n mediaCompanions.set(baseKey, []);\n }\n mediaCompanions.get(baseKey).push(extension);\n }\n \n // Track subtitle companions (TXT/SRT)\n if (extension === 'txt' || extension === 'srt') {\n const baseKey = `${directory}/${nameWithoutExt}`;\n if (!companionFiles.has(baseKey)) {\n companionFiles.set(baseKey, []);\n }\n companionFiles.get(baseKey).push(extension);\n }\n }\n });\n}\n\n// Find media files with missing companions\nconst mediaWithMissingCompanions = mediaFiles.filter(media => {\n const baseKey = `${media.directory}/${media.nameWithoutExt}`;\n const subtitleCompanions = companionFiles.get(baseKey) || [];\n const mediaCompanionsList = mediaCompanions.get(baseKey) || [];\n \n // Check if missing subtitle files OR missing media companion\n const missingSubtitles = !subtitleCompanions.includes('txt') && !subtitleCompanions.includes('srt');\n const missingMediaCompanion = (media.extension === 'mp3' && !mediaCompanionsList.includes('mp4')) ||\n (media.extension === 'mp4' && !mediaCompanionsList.includes('mp3'));\n \n // Return true if missing any companion\n return missingSubtitles || missingMediaCompanion;\n}).map(media => {\n const baseKey = `${media.directory}/${media.nameWithoutExt}`;\n const subtitleCompanions = companionFiles.get(baseKey) || [];\n const mediaCompanionsList = mediaCompanions.get(baseKey) || [];\n \n return {\n json: {\n ...media,\n mediaType: media.extension.toUpperCase(),\n missingCompanions: {\n // Subtitle companions\n hasTxt: subtitleCompanions.includes('txt'),\n hasSrt: subtitleCompanions.includes('srt'),\n missingSubtitles: !subtitleCompanions.includes('txt') && !subtitleCompanions.includes('srt'),\n \n // Media companions\n hasMp3: mediaCompanionsList.includes('mp3'),\n hasMp4: mediaCompanionsList.includes('mp4'),\n missingMp3: media.extension === 'mp4' && !mediaCompanionsList.includes('mp3'),\n missingMp4: media.extension === 'mp3' && !mediaCompanionsList.includes('mp4'),\n \n // Summary\n existingSubtitleCompanions: subtitleCompanions,\n existingMediaCompanions: mediaCompanionsList,\n missingTypes: [\n ...(!subtitleCompanions.includes('txt') && !subtitleCompanions.includes('srt') ? ['subtitles'] : []),\n ...(media.extension === 'mp3' && !mediaCompanionsList.includes('mp4') ? ['mp4'] : []),\n ...(media.extension === 'mp4' && !mediaCompanionsList.includes('mp3') ? ['mp3'] : [])\n ]\n }\n }\n };\n});\n\nreturn mediaWithMissingCompanions;"
},
"type": "n8n-nodes-base.code",
"typeVersion": 2,
"position": [
-2688,
576
],
"id": "8fcb2fb4-b968-4d33-a251-ee5aff31b373",
"name": "Obtain missing transcript files"
},
{
"parameters": {
"options": {
"reset": false
}
},
"type": "n8n-nodes-base.splitInBatches",
"typeVersion": 3,
"position": [
-2240,
576
],
"id": "5ebaf1f4-9450-48a7-b98c-1807e57cb9cd",
"name": "Loop Over Items"
},
{
"parameters": {},
"type": "n8n-nodes-base.noOp",
"typeVersion": 1,
"position": [
-2016,
384
],
"id": "8d9b0141-ed1f-41eb-827e-9653f065f135",
"name": "No Operation, do nothing"
},
{
"parameters": {
"method": "POST",
"url": "http://host.docker.internal:9000/asr",
"sendQuery": true,
"queryParameters": {
"parameters": [
{
"name": "task",
"value": "transcribe"
},
{
"name": "language",
"value": "es"
},
{
"name": "output",
"value": "txt"
}
]
},
"sendBody": true,
"contentType": "multipart-form-data",
"bodyParameters": {
"parameters": [
{
"parameterType": "formBinaryData",
"name": "audio_file",
"inputDataFieldName": "=data"
}
]
},
"options": {
"allowUnauthorizedCerts": true,
"timeout": 10000000
}
},
"type": "n8n-nodes-base.httpRequest",
"typeVersion": 4.2,
"position": [
-448,
112
],
"id": "22c79bdd-2186-4232-a920-5bca7d48e9f2",
"name": "Transcribe"
},
{
"parameters": {
"resource": "file",
"owner": {
"__rl": true,
"value": "https://github.com/YOURUSERNAME",
"mode": "url"
},
"repository": {
"__rl": true,
"value": "YOURREPO",
"mode": "name"
},
"filePath": "={{ $('Loop Over Items').item.json.directory }}/{{ $('Loop Over Items').item.json.nameWithoutExt }}.txt",
"fileContent": "={{ $json.data }}",
"commitMessage": "={{ $('Loop Over Items').item.json.nameWithoutExt }}.txt created"
},
"type": "n8n-nodes-base.github",
"typeVersion": 1.1,
"position": [
-224,
112
],
"id": "5af0ecb1-2eb3-40ec-8dc8-798ad7a5e3cf",
"name": "Create TXT File",
"webhookId": "40d8c3ab-8fd7-46d6-a053-9e7fb624ead7",
"credentials": {
"githubApi": {
"id": "2WWlazd5c5GnQjvq",
"name": "GitHub account 2"
}
},
"onError": "continueRegularOutput"
},
{
"parameters": {
"url": "={{ $json.download_url }}",
"options": {}
},
"type": "n8n-nodes-base.httpRequest",
"typeVersion": 4.2,
"position": [
-896,
576
],
"id": "bd6d6dbc-5097-4028-9caa-26e0e4ec5639",
"name": "Obtain MP3 Binary"
},
{
"parameters": {
"resource": "file",
"operation": "get",
"owner": {
"__rl": true,
"value": "https://github.com/YOURUSERNAME",
"mode": "url"
},
"repository": {
"__rl": true,
"value": "YOURREPO",
"mode": "name"
},
"filePath": "={{ $('Loop Over Items').item.json.path }}",
"asBinaryProperty": false,
"additionalParameters": {}
},
"type": "n8n-nodes-base.github",
"typeVersion": 1.1,
"position": [
-1120,
576
],
"id": "5db10bcc-265c-4bdb-a969-e808ad8a72cd",
"name": "Obtain File Details",
"webhookId": "b5b90aa8-3915-44db-80ec-3648472cb178",
"alwaysOutputData": false,
"credentials": {
"githubApi": {
"id": "2WWlazd5c5GnQjvq",
"name": "GitHub account 2"
}
}
},
{
"parameters": {
"mode": "insert",
"tableName": {
"__rl": true,
"value": "documents",
"mode": "list",
"cachedResultName": "documents"
},
"options": {}
},
"type": "@n8n/n8n-nodes-langchain.vectorStoreSupabase",
"typeVersion": 1.3,
"position": [
0,
0
],
"id": "2dd57b70-33f0-4cad-8d50-3c16e0948e40",
"name": "Supabase Vector Store",
"credentials": {
"supabaseApi": {
"id": "jCeYR9wmKXPeV8F9",
"name": "Supabase account 2"
}
}
},
{
"parameters": {
"jsonMode": "expressionData",
"jsonData": "={{ $('Transcribe').item.json.data }}",
"options": {}
},
"type": "@n8n/n8n-nodes-langchain.documentDefaultDataLoader",
"typeVersion": 1.1,
"position": [
224,
240
],
"id": "a0b9c96c-1dc7-4981-b210-b89d821a4bd2",
"name": "Default Data Loader"
},
{
"parameters": {
"model": "llama3.1:8b"
},
"type": "@n8n/n8n-nodes-langchain.embeddingsOllama",
"typeVersion": 1,
"position": [
16,
224
],
"id": "bdfdf5db-da69-4f79-9a5f-15fd782b0d5e",
"name": "Embeddings Ollama",
"credentials": {
"ollamaApi": {
"id": "sNEtnBkzxiRdrdMi",
"name": "Ollama account 2"
}
}
},
{
"parameters": {
"operation": "search",
"base": {
"__rl": true,
"value": "YOURACCOUNT",
"mode": "list",
"cachedResultName": "GamerTV",
"cachedResultUrl": "https://airtable.com/YOURACCOUNT"
},
"table": {
"__rl": true,
"value": "YOURTABLE",
"mode": "list",
"cachedResultName": "ProcessedPodcasts",
"cachedResultUrl": "https://airtable.com/YOURACCOUNT/YOURTABLE"
},
"filterByFormula": "=SEARCH(\"{{ $json.fileName }}\", {Name}) = 1 ",
"options": {}
},
"type": "n8n-nodes-base.airtable",
"typeVersion": 2.1,
"position": [
-2016,
576
],
"id": "5a31692d-d5d6-4f6e-ae74-302781f8608c",
"name": "Search Tracker Record",
"alwaysOutputData": true,
"credentials": {
"airtableTokenApi": {
"id": "PUvcTLN2cpZVPFO2",
"name": "Airtable Personal Access Token account 2"
}
}
},
{
"parameters": {
"conditions": {
"options": {
"caseSensitive": true,
"leftValue": "",
"typeValidation": "strict",
"version": 2
},
"conditions": [
{
"id": "ba0e54cc-81fb-48cc-9ebf-33ea93b03b7d",
"leftValue": "={{ $json.isEmpty()}}",
"rightValue": 1,
"operator": {
"type": "boolean",
"operation": "true",
"singleValue": true
}
}
],
"combinator": "and"
},
"options": {}
},
"type": "n8n-nodes-base.if",
"typeVersion": 2.2,
"position": [
-1792,
576
],
"id": "fcc747d6-1185-427a-a186-23176733576e",
"name": "If Tracker Does Not Exists"
},
{
"parameters": {
"operation": "create",
"base": {
"__rl": true,
"value": "YOURACCOUNT",
"mode": "list",
"cachedResultName": "GamerTV",
"cachedResultUrl": "https://airtable.com/YOURACCOUNT"
},
"table": {
"__rl": true,
"value": "YOURTABLE",
"mode": "list",
"cachedResultName": "ProcessedPodcasts",
"cachedResultUrl": "https://airtable.com/YOURACCOUNT/YOURTABLE"
},
"columns": {
"mappingMode": "defineBelow",
"value": {
"TXT": false,
"SRT": false,
"MP4": false,
"UploadedToYoutube": false,
"Name": "={{ $('Loop Over Items').item.json.fileName }}"
},
"matchingColumns": [
"Name"
],
"schema": [
{
"id": "Name",
"displayName": "Name",
"required": false,
"defaultMatch": false,
"canBeUsedToMatch": true,
"display": true,
"type": "string",
"readOnly": false,
"removed": false
},
{
"id": "TXT",
"displayName": "TXT",
"required": false,
"defaultMatch": false,
"canBeUsedToMatch": true,
"display": true,
"type": "boolean",
"readOnly": false,
"removed": false
},
{
"id": "SRT",
"displayName": "SRT",
"required": false,
"defaultMatch": false,
"canBeUsedToMatch": true,
"display": true,
"type": "boolean",
"readOnly": false,
"removed": false
},
{
"id": "MP4",
"displayName": "MP4",
"required": false,
"defaultMatch": false,
"canBeUsedToMatch": true,
"display": true,
"type": "boolean",
"readOnly": false,
"removed": false
},
{
"id": "UploadedToYoutube",
"displayName": "UploadedToYoutube",
"required": false,
"defaultMatch": false,
"canBeUsedToMatch": true,
"display": true,
"type": "boolean",
"readOnly": false,
"removed": false
}
],
"attemptToConvertTypes": false,
"convertFieldsToString": false
},
"options": {}
},
"type": "n8n-nodes-base.airtable",
"typeVersion": 2.1,
"position": [
-1568,
496
],
"id": "7cbaf0a6-c76a-4ac9-8218-2030087f6d10",
"name": "Create Tracker Record",
"credentials": {
"airtableTokenApi": {
"id": "PUvcTLN2cpZVPFO2",
"name": "Airtable Personal Access Token account 2"
}
}
},
{
"parameters": {
"conditions": {
"options": {
"caseSensitive": true,
"leftValue": "",
"typeValidation": "strict",
"version": 2
},
"conditions": [
{
"id": "258bdf88-32eb-40a3-aaf0-02613d664f4e",
"leftValue": "={{ $('Loop Over Items').item.json.missingCompanions.hasTxt }}",
"rightValue": "",
"operator": {
"type": "boolean",
"operation": "false",
"singleValue": true
}
}
],
"combinator": "and"
},
"options": {}
},
"type": "n8n-nodes-base.if",
"typeVersion": 2.2,
"position": [
-672,
304
],
"id": "78998206-32ca-4aa2-8efa-ffd924f9e120",
"name": "If TXT Does not exist"
},
{
"parameters": {},
"type": "n8n-nodes-base.noOp",
"typeVersion": 1,
"position": [
576,
640
],
"id": "e6c5a25d-af29-44cb-886a-93850cc9b786",
"name": "No Operation, do nothing2"
},
{
"parameters": {
"conditions": {
"options": {
"caseSensitive": true,
"leftValue": "",
"typeValidation": "strict",
"version": 2
},
"conditions": [
{
"id": "c458e703-e72e-4061-aec0-633bc5fb3880",
"leftValue": "={{ $('Loop Over Items').item.json.missingCompanions.hasSrt }}",
"rightValue": "",
"operator": {
"type": "boolean",
"operation": "false",
"singleValue": true
}
}
],
"combinator": "and"
},
"options": {}
},
"type": "n8n-nodes-base.if",
"typeVersion": 2.2,
"position": [
-448,
592
],
"id": "84bb5097-aa50-416c-9604-24dd3a3945e3",
"name": "If SRT Does not exist"
},
{
"parameters": {
"operation": "update",
"base": {
"__rl": true,
"value": "YOURACCOUNT",
"mode": "list",
"cachedResultName": "GamerTV",
"cachedResultUrl": "https://airtable.com/YOURACCOUNT"
},
"table": {
"__rl": true,
"value": "YOURTABLE",
"mode": "list",
"cachedResultName": "ProcessedPodcasts",
"cachedResultUrl": "https://airtable.com/YOURACCOUNT/YOURTABLE"
},
"columns": {
"mappingMode": "defineBelow",
"value": {
"TXT": true,
"Vectorized": true,
"id": "={{ $('Merge').item.json.id }}"
},
"matchingColumns": [
"id"
],
"schema": [
{
"id": "id",
"displayName": "id",
"required": false,
"defaultMatch": true,
"display": true,
"type": "string",
"readOnly": true,
"removed": false
},
{
"id": "Name",
"displayName": "Name",
"required": false,
"defaultMatch": false,
"canBeUsedToMatch": true,
"display": true,
"type": "string",
"readOnly": false,
"removed": true
},
{
"id": "TXT",
"displayName": "TXT",
"required": false,
"defaultMatch": false,
"canBeUsedToMatch": true,
"display": true,
"type": "boolean",
"readOnly": false,
"removed": false
},
{
"id": "SRT",
"displayName": "SRT",
"required": false,
"defaultMatch": false,
"canBeUsedToMatch": true,
"display": true,
"type": "boolean",
"readOnly": false,
"removed": true
},
{
"id": "MP4",
"displayName": "MP4",
"required": false,
"defaultMatch": false,
"canBeUsedToMatch": true,
"display": true,
"type": "boolean",
"readOnly": false,
"removed": true
},
{
"id": "UploadedToYoutube",
"displayName": "UploadedToYoutube",
"required": false,
"defaultMatch": false,
"canBeUsedToMatch": true,
"display": true,
"type": "boolean",
"readOnly": false,
"removed": true
},
{
"id": "Vectorized",
"displayName": "Vectorized",
"required": false,
"defaultMatch": false,
"canBeUsedToMatch": true,
"display": true,
"type": "boolean",
"readOnly": false,
"removed": false
}
],
"attemptToConvertTypes": false,
"convertFieldsToString": false
},
"options": {}
},
"type": "n8n-nodes-base.airtable",
"typeVersion": 2.1,
"position": [
352,
112
],
"id": "33a4cd32-2c37-4c64-94e5-b06f4a87e3b4",
"name": "Update record",
"credentials": {
"airtableTokenApi": {
"id": "PUvcTLN2cpZVPFO2",
"name": "Airtable Personal Access Token account 2"
}
}
},
{
"parameters": {},
"type": "n8n-nodes-base.merge",
"typeVersion": 3.2,
"position": [
-1344,
576
],
"id": "657b0d06-d65f-4c35-8175-004da4b1e715",
"name": "Merge"
},
{
"parameters": {
"method": "POST",
"url": "http://host.docker.internal:9000/asr",
"sendQuery": true,
"queryParameters": {
"parameters": [
{
"name": "task",
"value": "transcribe"
},
{
"name": "language",
"value": "es"
},
{
"name": "output",
"value": "srt"
}
]
},
"sendBody": true,
"contentType": "multipart-form-data",
"bodyParameters": {
"parameters": [
{
"parameterType": "formBinaryData",
"name": "audio_file",
"inputDataFieldName": "=data"
}
]
},
"options": {
"allowUnauthorizedCerts": true,
"timeout": 10000000
}
},
"type": "n8n-nodes-base.httpRequest",
"typeVersion": 4.2,
"position": [
-224,
496
],
"id": "7550f240-f4c2-488e-af07-be398e7def75",
"name": "Transcribe SRT"
},
{
"parameters": {
"resource": "file",
"owner": {
"__rl": true,
"value": "https://github.com/YOURUSERNAME",
"mode": "url"
},
"repository": {
"__rl": true,
"value": "YOURREPO",
"mode": "name"
},
"filePath": "={{ $('Loop Over Items').item.json.directory }}/{{ $('Loop Over Items').item.json.nameWithoutExt }}.srt",
"fileContent": "={{ $json.data }}",
"commitMessage": "={{ $('Loop Over Items').item.json.nameWithoutExt }}.srt created"
},
"type": "n8n-nodes-base.github",
"typeVersion": 1.1,
"position": [
64,
496
],
"id": "088ab9c4-041f-4509-b3b3-bf8b0cd746a3",
"name": "Create SRT",
"webhookId": "40d8c3ab-8fd7-46d6-a053-9e7fb624ead7",
"credentials": {
"githubApi": {
"id": "2WWlazd5c5GnQjvq",
"name": "GitHub account 2"
}
},
"onError": "continueRegularOutput"
},
{
"parameters": {
"operation": "update",
"base": {
"__rl": true,
"value": "YOURACCOUNT",
"mode": "list",
"cachedResultName": "GamerTV",
"cachedResultUrl": "https://airtable.com/YOURACCOUNT"
},
"table": {
"__rl": true,
"value": "YOURTABLE",
"mode": "list",
"cachedResultName": "ProcessedPodcasts",
"cachedResultUrl": "https://airtable.com/YOURACCOUNT/YOURTABLE"
},
"columns": {
"mappingMode": "defineBelow",
"value": {
"id": "={{ $('Merge').item.json.id }}",
"SRT": true
},
"matchingColumns": [
"id"
],
"schema": [
{
"id": "id",
"displayName": "id",
"required": false,
"defaultMatch": true,
"display": true,
"type": "string",
"readOnly": true,
"removed": false
},
{
"id": "Name",
"displayName": "Name",
"required": false,
"defaultMatch": false,
"canBeUsedToMatch": true,
"display": true,
"type": "string",
"readOnly": false,
"removed": true
},
{
"id": "TXT",
"displayName": "TXT",
"required": false,
"defaultMatch": false,
"canBeUsedToMatch": true,
"display": true,
"type": "boolean",
"readOnly": false,
"removed": true
},
{
"id": "SRT",
"displayName": "SRT",
"required": false,
"defaultMatch": false,
"canBeUsedToMatch": true,
"display": true,
"type": "boolean",
"readOnly": false,
"removed": false
},
{
"id": "MP4",
"displayName": "MP4",
"required": false,
"defaultMatch": false,
"canBeUsedToMatch": true,
"display": true,
"type": "boolean",
"readOnly": false,
"removed": true
},
{
"id": "UploadedToYoutube",
"displayName": "UploadedToYoutube",
"required": false,
"defaultMatch": false,
"canBeUsedToMatch": true,
"display": true,
"type": "boolean",
"readOnly": false,
"removed": true
},
{
"id": "Vectorized",
"displayName": "Vectorized",
"required": false,
"defaultMatch": false,
"canBeUsedToMatch": true,
"display": true,
"type": "boolean",
"readOnly": false,
"removed": true
}
],
"attemptToConvertTypes": false,
"convertFieldsToString": false
},
"options": {}
},
"type": "n8n-nodes-base.airtable",
"typeVersion": 2.1,
"position": [
352,
496
],
"id": "e87e543e-b528-4a53-962a-84c75435f21e",
"name": "Update record srt",
"credentials": {
"airtableTokenApi": {
"id": "PUvcTLN2cpZVPFO2",
"name": "Airtable Personal Access Token account 2"
}
}
},
{
"parameters": {
"conditions": {
"options": {
"caseSensitive": true,
"leftValue": "",
"typeValidation": "strict",
"version": 2
},
"conditions": [
{
"id": "a67f95a5-08e0-4196-ae93-10842ba5f735",
"leftValue": "={{ $json.missingCompanions.hasTxt }}",
"rightValue": "",
"operator": {
"type": "boolean",
"operation": "false",
"singleValue": true
}
},
{
"id": "563b22c2-396a-4f65-a6b3-ef0d3f5573cd",
"leftValue": "={{ $json.missingCompanions.hasSrt }}",
"rightValue": "",
"operator": {
"type": "boolean",
"operation": "false",
"singleValue": true
}
}
],
"combinator": "or"
},
"options": {}
},
"type": "n8n-nodes-base.filter",
"typeVersion": 2.2,
"position": [
-2464,
576
],
"id": "0df44cbe-b843-418e-8c3d-338b2700e6a4",
"name": "Filter"
}
],
"pinData": {},
"connections": {
"When clicking ‘Execute workflow’": {
"main": [
[
{
"node": "Obtain recursive git",
"type": "main",
"index": 0
}
]
]
},
"Obtain recursive git": {
"main": [
[
{
"node": "Obtain missing transcript files",
"type": "main",
"index": 0
}
]
]
},
"Obtain missing transcript files": {
"main": [
[
{
"node": "Filter",
"type": "main",
"index": 0
}
]
]
},
"Loop Over Items": {
"main": [
[
{
"node": "No Operation, do nothing",
"type": "main",
"index": 0
}
],
[
{
"node": "Search Tracker Record",
"type": "main",
"index": 0
}
]
]
},
"Transcribe": {
"main": [
[
{
"node": "Create TXT File",
"type": "main",
"index": 0
}
]
]
},
"Create TXT File": {
"main": [
[
{
"node": "Supabase Vector Store",
"type": "main",
"index": 0
}
]
]
},
"Obtain MP3 Binary": {
"main": [
[
{
"node": "If TXT Does not exist",
"type": "main",
"index": 0
},
{
"node": "If SRT Does not exist",
"type": "main",
"index": 0
},
{
"node": "No Operation, do nothing2",
"type": "main",
"index": 0
}
]
]
},
"Obtain File Details": {
"main": [
[
{
"node": "Obtain MP3 Binary",
"type": "main",
"index": 0
}
]
]
},
"Supabase Vector Store": {
"main": [
[
{
"node": "Update record",
"type": "main",
"index": 0
}
]
]
},
"Default Data Loader": {
"ai_document": [
[
{
"node": "Supabase Vector Store",
"type": "ai_document",
"index": 0
}
]
]
},
"Embeddings Ollama": {
"ai_embedding": [
[
{
"node": "Supabase Vector Store",
"type": "ai_embedding",
"index": 0
}
]
]
},
"Search Tracker Record": {
"main": [
[
{
"node": "If Tracker Does Not Exists",
"type": "main",
"index": 0
}
]
]
},
"If Tracker Does Not Exists": {
"main": [
[
{
"node": "Create Tracker Record",
"type": "main",
"index": 0
}
],
[
{
"node": "Merge",
"type": "main",
"index": 1
}
]
]
},
"Create Tracker Record": {
"main": [
[
{
"node": "Merge",
"type": "main",
"index": 0
}
]
]
},
"If TXT Does not exist": {
"main": [
[
{
"node": "Transcribe",
"type": "main",
"index": 0
}
],
[
{
"node": "No Operation, do nothing2",
"type": "main",
"index": 0
}
]
]
},
"No Operation, do nothing2": {
"main": [
[
{
"node": "Loop Over Items",
"type": "main",
"index": 0
}
]
]
},
"If SRT Does not exist": {
"main": [
[
{
"node": "Transcribe SRT",
"type": "main",
"index": 0
}
],
[
{
"node": "No Operation, do nothing2",
"type": "main",
"index": 0
}
]
]
},
"Update record": {
"main": [
[
{
"node": "No Operation, do nothing2",
"type": "main",
"index": 0
}
]
]
},
"Merge": {
"main": [
[
{
"node": "Obtain File Details",
"type": "main",
"index": 0
}
]
]
},
"Transcribe SRT": {
"main": [
[
{
"node": "Create SRT",
"type": "main",
"index": 0
}
]
]
},
"Create SRT": {
"main": [
[
{
"node": "Update record srt",
"type": "main",
"index": 0
}
]
]
},
"Update record srt": {
"main": [
[
{
"node": "No Operation, do nothing2",
"type": "main",
"index": 0
}
]
]
},
"Filter": {
"main": [
[
{
"node": "Loop Over Items",
"type": "main",
"index": 0
}
]
]
}
},
"active": false,
"settings": {
"executionOrder": "v1"
},
"versionId": "bccbd729-643b-439d-a626-1ef84f72b047",
"meta": {
"templateCredsSetupCompleted": true,
"instanceId": "75a365ea8240d65c99f94c3771c1d8d00b86c8549270015ed7dce6ffb7f28af7"
},
"id": "mw4urVAAtOfoyeZv",
"tags": []
}Workflow Walkthrough
- GitHub List Repo Files – scan repository for
.mp3files. - Function Node – check if transcripts (
.txt,.srt) are missing. - Airtable Lookup/Create – register the episode.
- Whisper ASR (HTTP Request Nodes) – transcribe audio into TXT and SRT.
- GitHub Commit – push transcripts back into the repo.
- Ollama Embeddings – create embeddings with Llama3.1:8b.
- Supabase Insert – persist transcript, metadata, embeddings.
- Airtable Update – mark episode as
TranscribedandVectorized
Architecture
We’ll look at this from two perspectives:
- C4 Architecture Diagram – systems and their relationships.
- n8n Flow Diagram – execution path inside n8n.
C4 Architecture Diagram
@startuml
title Podcast Ingestion Pipeline with n8n
!include <C4/C4_Container>
AddContainerTag("worker", $legendText="Worker/Automation")
AddContainerTag("store", $legendText="Storage")
AddContainerTag("tracker",$legendText="Tracker/Config")
AddContainerTag("ml", $legendText="ML/Embeddings")
Person(admin, "Maintainer", "Ops/dev who runs the pipeline")
System_Boundary(n8n, "n8n Workflow") {
Container(githubNode, "GitHub Node", "Fetch/commit audio & transcripts", $tags="worker")
Container(airtableNode, "Airtable Node", "Track progress", $tags="tracker")
Container(whisperNode, "HTTP Whisper ASR Nodes", "Send audio → Get TXT/SRT", $tags="ml")
Container(ollamaNode, "Ollama Node", "Generate embeddings (Llama3.1:8b)", $tags="ml")
Container(supabaseNode, "Supabase Node", "Insert transcripts + embeddings", $tags="store")
}
@enduml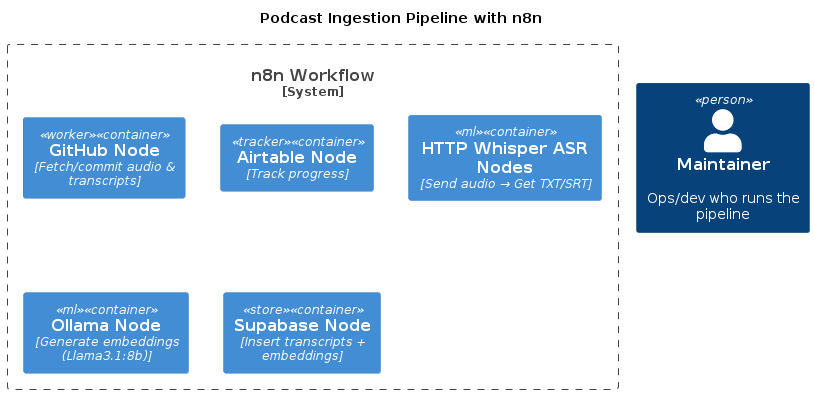
n8n Workflow Flow Diagram
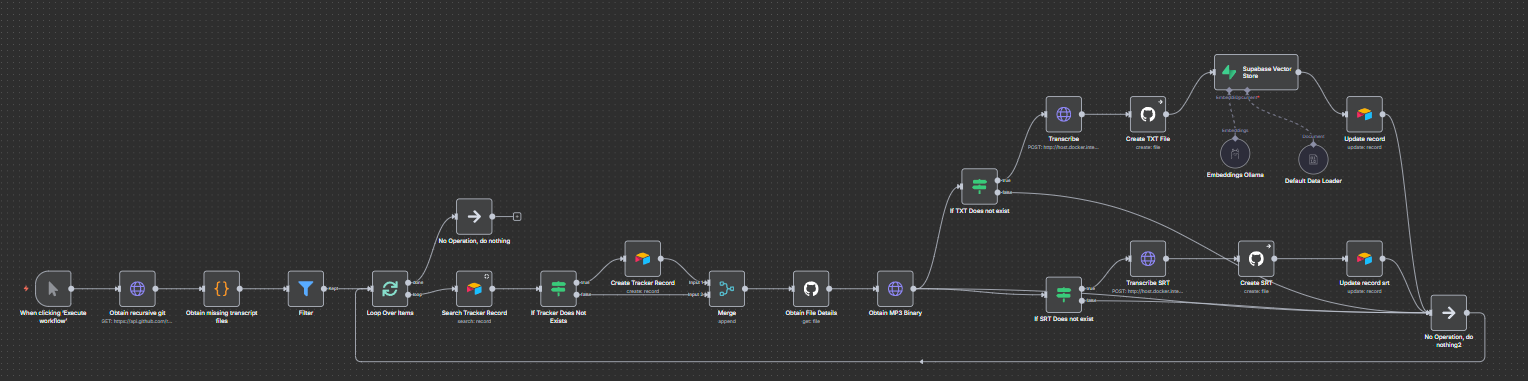
You will need to change to your user name, repo, air table tables and supabase credentials as well github credentials. You just need to import the workflow and change these settings. Also you can copy individual nodes and take whatever you need.
Conclusion
With n8n as the automation hub, plus Airtable, Supabase, Whisper ASR WebService, and Ollama, we now have a fully automated ingestion pipeline for our podcast:
- n8n orchestrates with GitHub, Airtable, Whisper, and Supabase nodes.
- Airtable tracks state and progress.
- Whisper ASR provides high-quality transcripts.
- Ollama generates embeddings.
- Supabase stores text and vectors.
This workflow makes it easy to transcribe and enrich every episode automatically, freeing us from repetitive manual work.
Next up: we’ll create a dedicated post on how to search the vector database with n8n — turning this ingestion pipeline into a full-blown semantic podcast search engine.
👉 Question for readers: which n8n node do you rely on most when building automations — HTTP Request, Function, or database connectors?
Happy Coding!!!