
Build Your Own Local AI Automation Hub with n8n + Ollama (No Cloud Required!)

If you’ve been playing with local LLMs like Llama 3.1 (8B) and are a fan of automation tools like n8n, you’re in for a treat.
Today, we’ll connect n8n to your local Ollama instance (with Open WebUI) using Docker Compose.
The result? Automated AI workflows that you can run from the comfort of your machine—no cloud subscription required.
We’ll go step-by-step:
- Prerequisites — ensuring Docker is ready to go.
- GPU considerations — running Ollama efficiently on your hardware.
- Docker Compose setup for both n8n and Ollama (with Open WebUI).
- Starting the containers with
docker compose up -d. - Pulling an LLM model into Ollama (and choosing the right one).
- Configuring n8n to talk to Ollama’s API.
- Troubleshooting — resolving API connection issues.
- Use cases & practical examples — what you can automate today.
- Architecture diagram — how the components connect.
- n8n sample AI integration
Prerequisites
Before we start, make sure Docker is installed and working:
- Linux → Install Docker Engine following the official guide.
After installation, verify with:
docker --version
- Windows → Install Docker Desktop.
Ensure it’s running and WSL2 integration is enabled.
docker compose version
Once Docker is up and running, we can build the automation stack.
GPU Considerations
Ollama can use your system’s GPU to accelerate model inference—this makes a huge difference in performance.
- NVIDIA GPUs → Supported out-of-the-box in the Docker container if you have the NVIDIA Container Toolkit installed (setup guide).
- AMD GPUs → The official Docker image currently focuses on NVIDIA, but you can still use AMD cards by installing the Ollama desktop application (download here).
The desktop app will detect and use AMD hardware directly, and you can still connect n8n to it via the same API endpoints.
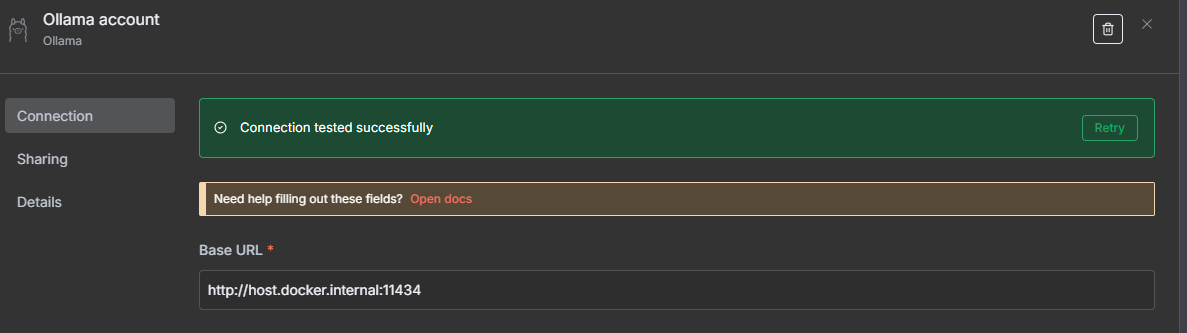
Note: When using the desktop app, try connecting from n8n to:
http://localhost:11434If that doesn’t work from inside a Docker container, use:
http://host.docker.internal:11434host.docker.internal allows containers to talk to services running on the host machine.
If you have no GPU, Ollama will still run on CPU—just be aware that performance will be slower.
Setting Up the Docker Compose Files
We’ll use two stacks—one for n8n, one for ollama + Open WebUI.
Feel free to adjust the TZ value to your time zone.
n8n Docker Compose
services:
n8n:
image: n8nio/n8n:latest
container_name: n8n
ports:
- "5678:5678"
environment:
- TZ=America/Los_Angeles
- GENERIC_TIMEZONE=America/Los_Angeles
- N8N_BASIC_AUTH_ACTIVE=true
- N8N_BASIC_AUTH_USER=admin
- N8N_BASIC_AUTH_PASSWORD=changeme
volumes:
- n8n_data:/home/node/.n8n
restart: unless-stopped
volumes:
n8n_data:
Ollama + Open WebUI Docker Compose
services:
ollama:
image: ollama/ollama:latest
container_name: ollama
ports:
- "11434:11434"
volumes:
- ollama_data:/root/.ollama
restart: unless-stopped
open-webui:
image: ghcr.io/open-webui/open-webui:main
container_name: open-webui
ports:
- "3000:8080"
environment:
- OLLAMA_BASE_URL=http://ollama:11434
depends_on:
- ollama
restart: unless-stopped
volumes:
ollama_data:
Bringing Containers Up
Once you’ve saved the files (docker-compose.n8n.yml and docker-compose.ollama.yml for example), spin them up:
docker compose -f docker-compose.n8n.yml up -d
docker compose -f docker-compose.ollama.yml up -d
You should now have:
- n8n on http://localhost:5678
- Open WebUI on http://localhost:3000
- Ollama API on
http://localhost:11434
Downloading an LLM Model
Ollama ships without models by default.
To pull Llama 3.1 (8B), run:
docker exec -it ollama ollama pull llama3.1:8b
You can replace llama3.1:8b with mistral, gemma, deepseek, or any model listed at ollama.com/library.
Tip:
Different models shine in different scenarios—choose based on your use case.
| Model | Strengths | Weaknesses | Best Use Cases |
|---|---|---|---|
| Gemma | Excellent translation quality, multilingual support | Slightly slower on large prompts | Language translation, text transformation |
| Llama 3.1 (8B) | Strong reasoning, context retention, agent-like behavior | Larger memory footprint | AI agents, long-form content, multi-step workflows |
| DeepSeek | Very fast response times, lightweight | Can be less accurate on complex queries | Quick answers, lightweight automation, high-volume requests |
You can install multiple models and switch between them in n8n depending on the task—ideal for hybrid automation workflows.
Connecting n8n to Ollama’s API
With Ollama running, you can access its REST API at:
POST http://ollama:11434/api/generate
Example n8n HTTP Request node:
Method: POST
URL: http://ollama:11434/api/generate
Headers: Content-Type: application/json
- Body:
{
"model": "llama3.1:8b",
"prompt": "Write a haiku about local AI automation"
}
Troubleshooting: Ollama API Not Resolving in n8n
Sometimes when running both n8n and Ollama in Docker, the API calls from n8n may fail with a connection error like:
Error: connect ECONNREFUSED
This often happens because the container cannot resolve http://ollama:11434 by name.
Quick Fix:
- First, try:
http://localhost:11434
2. If that doesn't work from inside a container, switch to:
http://host.docker.internal:11434
host.docker.internal is a special DNS name that resolves to your Docker host machine, allowing containers to communicate with services running outside their own network.
Use Cases & Practical Examples
n8n isn’t just an automation platform—it’s the glue that can connect virtually any API, database, or service to your AI workflows.
When paired with Ollama, you can bring local AI power into the mix for advanced text generation, translation, summarization, and decision-making.
Here are some real-world scenarios:
| Use Case | How n8n Helps | AI’s Role |
|---|---|---|
| Content Summarization | Pull long-form content from RSS feeds, newsletters, or APIs. | Use LLM to generate concise, shareable summaries. |
| Customer Support Automation | Listen to support tickets from email or helpdesk APIs. | Use LLM to draft responses or classify priority. |
| Data Enrichment | Gather structured data from a CRM or database. | LLM adds missing details or formats it into reports. |
| Language Translation | Pull multilingual content from APIs. | LLM translates into the target language. |
| Idea Generation | Trigger workflows from a form submission. | LLM generates brainstorm ideas, drafts, or outlines. |
Practical Example: Video Game RSS Translation & Social Publishing
Let’s say you run a multilingual gaming news account and want to automate your content posting. Here’s the workflow:
RSS Trigger — n8n monitors an RSS feed from a popular video game site.
Fetch & Parse Content — The RSS data (title, link, description) is parsed in n8n.
Translate via Ollama —
n8n sends the article text to Ollama running the Gemma model for high-quality translations.
Format for Social Media — Trim content to platform limits and add hashtags.
- Multi-Platform Publish — Post to Twitter/X, Facebook, and Mastodon.
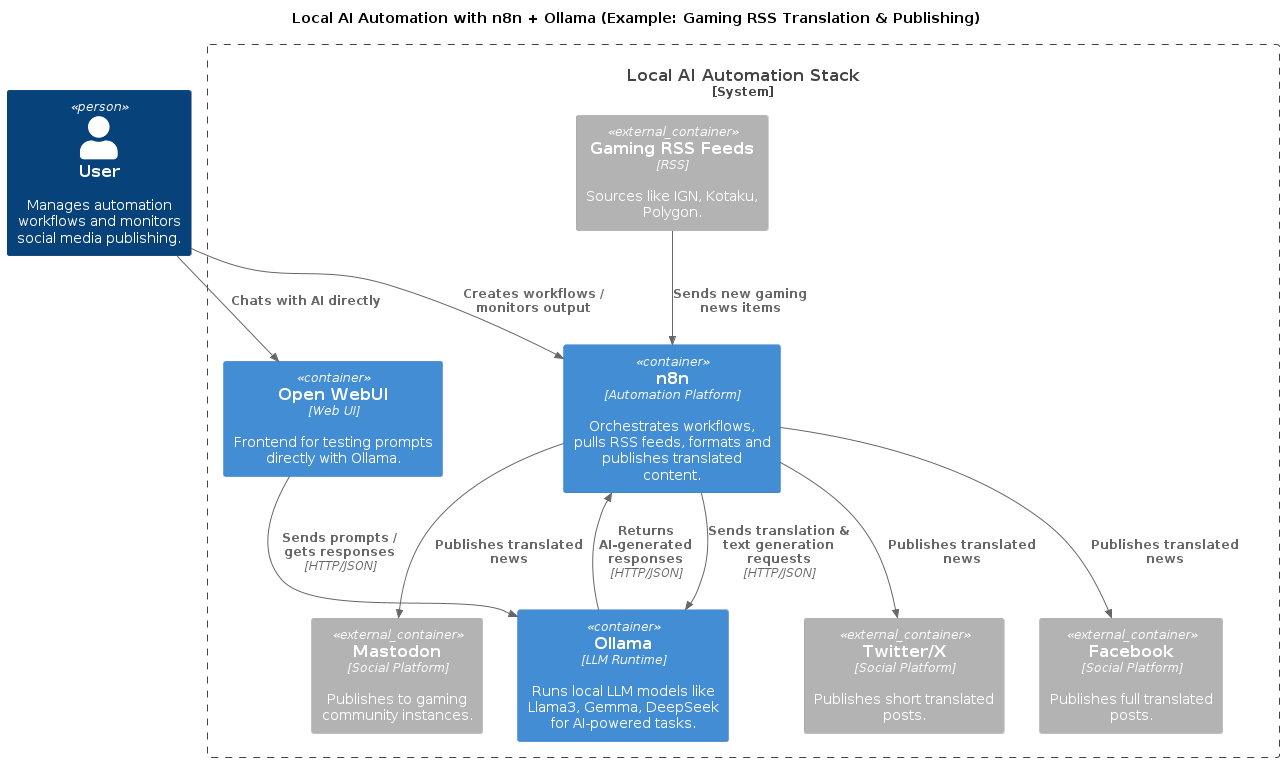
Architecture Diagram
@startuml
!include <C4/C4_Container>
title Local AI Automation with n8n + Ollama (Example: Gaming RSS Translation & Publishing)
Person(user, "User", "Manages automation workflows and monitors social media publishing.")
System_Boundary(localStack, "Local AI Automation Stack") {
Container(n8n, "n8n", "Automation Platform", "Orchestrates workflows, pulls RSS feeds, formats and publishes translated content.")
Container(ollama, "Ollama", "LLM Runtime", "Runs local LLM models like Llama3.1:8b, Gemma, DeepSeek for AI-powered tasks.")
Container(openwebui, "Open WebUI", "Web UI", "Frontend for testing prompts directly with Ollama.")
Container_Ext(rssfeed, "Gaming RSS Feeds", "RSS", "Sources like IGN, Kotaku, Polygon.")
Container_Ext(twitter, "Twitter/X", "Social Platform", "Publishes short translated posts.")
Container_Ext(facebook, "Facebook", "Social Platform", "Publishes full translated posts.")
Container_Ext(mastodon, "Mastodon", "Social Platform", "Publishes to gaming community instances.")
}
Rel(user, n8n, "Creates workflows / monitors output")
Rel(user, openwebui, "Chats with AI directly")
Rel(n8n, ollama, "Sends translation & text generation requests", "HTTP/JSON")
Rel(openwebui, ollama, "Sends prompts / gets responses", "HTTP/JSON")
Rel(ollama, n8n, "Returns AI-generated responses", "HTTP/JSON")
Rel(rssfeed, n8n, "Sends new gaming news items")
Rel(n8n, twitter, "Publishes translated news")
Rel(n8n, facebook, "Publishes translated news")
Rel(n8n, mastodon, "Publishes translated news")
@enduml
Lets create the workflow
Open a browser and go to the url
http://localhost:5678/First time n8n will ask you to register and enter a key, don't worry it is free!!!
Next create a workflow
Next create a manual trigger, once you start playing with it you will see it is so easy to add more triggers (timer, webhook, telegram, etc)
Next click on the plus sign and add an rss feed
I will use Kokatu's rss feed
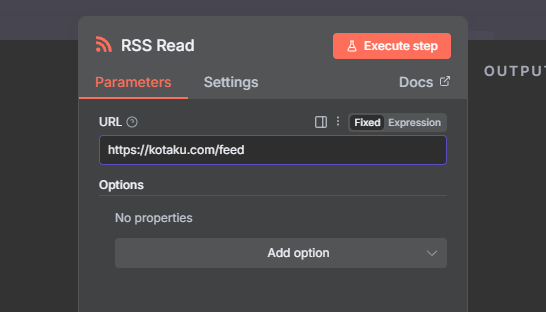
If you execute the step you will see the response from the feed

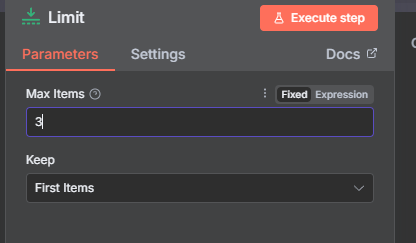
Now I will limit my items to the top 3, so i will add the limit node
Next comes the fun part, the Ollama chat model
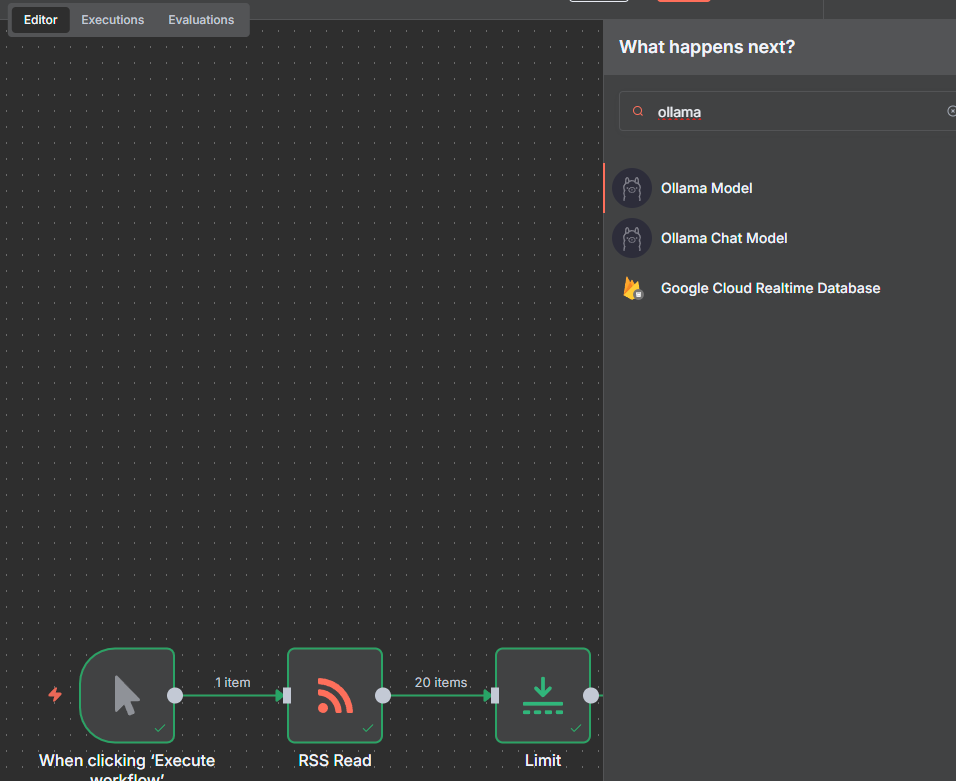
Create a new credential
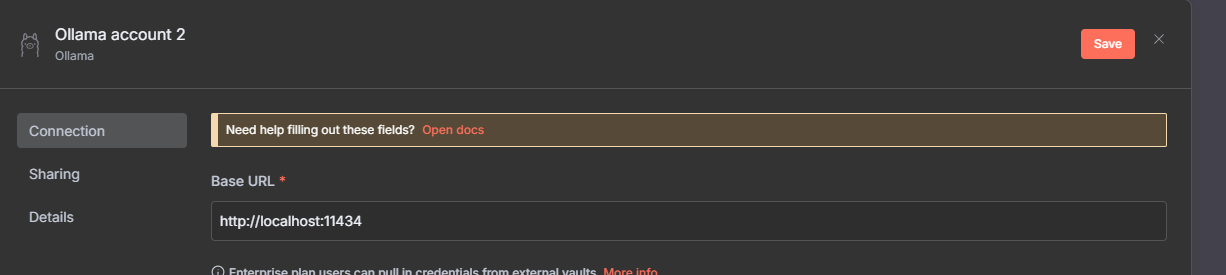
And surprise surprise, we need to enter the url for the API, if you have issues while saving, check the troubleshoot section
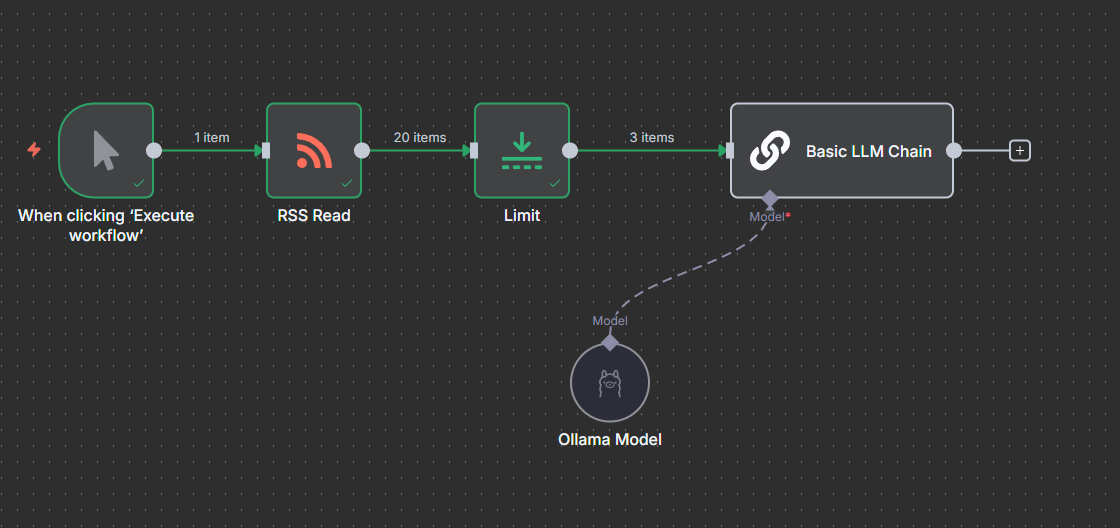
The workflow should look like
Now to translate the snippet
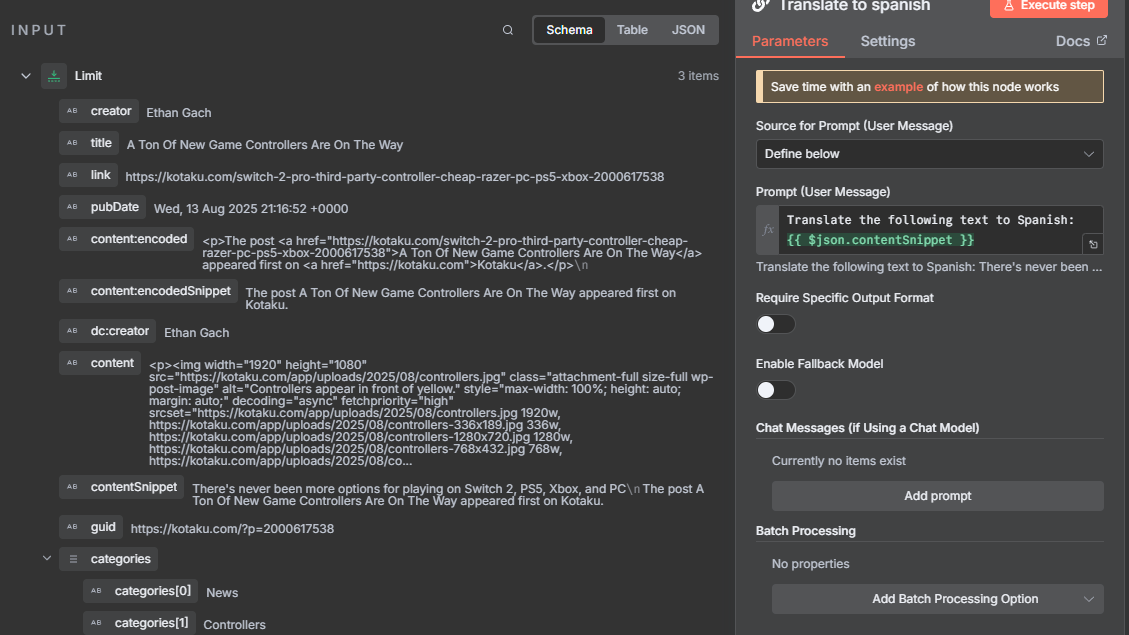
Note that we are defining the input from the previous node (the rss feed) and we can drag and drop the field we want to translate (encoded snippet)
Next I am using a prompt that states "Translate the following text to Spanish:" and the snippet/text to translate.
WHAT? yes it will translate, but you can do whatever you want with the text, you can say summarize or translate in a funny way.
You can also use it for AI agents, lets say, from this snippet can you check if it is true or give you more context. Â Obviously this is a local instance and it is not up to date but it is powerful enough to do tasks.
Let's execute the node and I see my GPU working


This is a small example but you can think of the possibilities
Wrap-Up
With this setup:
n8n orchestrates your automation. It’s a workflow automation platform that lets you connect APIs, databases, and services visually—similar to Zapier or Integromat, but open-source and self-hostable.
Ollama runs LLMs locally—fast, private, and internet-optional. It’s a local AI runtime that allows you to download and execute models like Llama 3.1, Gemma, or DeepSeek directly on your machine, with optional GPU acceleration.
Open WebUI gives you a friendly chat interface for testing prompts.
No API limits. No billing surprises. Just local power.
Next post I will show you how to create an AI agent and MCP!!! and maybe just maybe create an MCP C# Server with a sample API. This way the AI agent will know how to consume my API and automate it!!!
Happy coding!!!