
LLMs at Ludicrous Speed: Dockerizing vLLM for Real Apps

If you’ve ever watched your GPU twiddle its thumbs between prompts, this one’s for you. In this post we’ll cover what vLLM is, why it’s fast, how to run it with Docker Compose, and how to test it with real calls. I’ll also show concrete scenarios where vLLM’s scheduling + memory tricks turn into tangible wins for your apps.
What is vLLM (and why is it fast)?
vLLM is an open-source inference server that implements the OpenAI-style API (chat/completions) and focuses on throughput and latency at scale. Two ideas drive most of its speedups:
- Continuous batching: instead of waiting for a whole batch before running the next forward pass, vLLM continuously admits new requests/tokens into the active batch, keeping the GPU busy and reducing latency under load.
- PagedAttention: inspired by OS virtual memory, it stores the KV cache in “blocks†and reuses/evicts them efficiently. That means higher concurrency and longer contexts for the same memory, especially when prompts vary in length.
The punchline: across versions, vLLM has demonstrated multi-x throughput and latency gains versus naive serving baselines — while remaining API-compatible with OpenAI.
What is Hugging Face?
If vLLM is the engine, Hugging Face is the garage where you pick your car. 🚗
Hugging Face is the largest open-source hub for machine learning models, datasets, and tools. Think of it as GitHub, but for AI. Developers, researchers, and companies publish their trained models there — everything from BERT and GPT-style transformers to diffusion models for images.
Key reasons it matters for vLLM:
- Model hub: You can pull models like Meta Llama 3.1, Gemma, or Qwen2.5 directly from Hugging Face by referencing their repo names.
- Access control: Some models require you to accept license terms before downloading. For those, you’ll need a Hugging Face access token (API key you generate in your account).
- Ecosystem: Hugging Face also provides libraries like
transformers,datasets, andaccelerate.
That’s why in the Docker Compose file below we added an optional environment line:
- HUGGING_FACE_HUB_TOKEN=hf_xxx
If the model you want is gated, you pop your token in here, and vLLM will authenticate automatically when pulling it down.
Example 1: Open-access model (no token needed)
This pulls a model that anyone can download directly — for example, Qwen2.5:7B-Instruct.
# docker-compose.yml
version: "3.8"
services:
vllm:
image: vllm/vllm-openai:latest
container_name: vllm
tty: true
restart: unless-stopped
environment:
- TZ=America/Los_Angeles
command: >
--model Qwen/Qwen2.5-7B-Instruct
--dtype auto
--max-model-len 8192
--gpu-memory-utilization 0.90
--download-dir /models
--host 0.0.0.0
--port 8000
--api-key dev-key
ports:
- "8000:8000"
volumes:
- ./models:/models
deploy:
resources:
reservations:
devices:
- capabilities: ["gpu"]
Bring it up:
docker compose up -d
docker logs -f vllm
Example 2: Gated model (requires Hugging Face token)
For models like Meta Llama 3.1, you’ll need to:
- Create a Hugging Face account.
- Go to Settings → Access Tokens and generate a token.
- Accept the model’s license terms on its Hugging Face page.
Then add your token to the environment:
# docker-compose.yml
version: "3.8"
services:
vllm:
image: vllm/vllm-openai:latest
container_name: vllm
tty: true
restart: unless-stopped
environment:
- TZ=America/Los_Angeles
- HUGGING_FACE_HUB_TOKEN=hf_xxx # replace with your token
command: >
--model meta-llama/Meta-Llama-3.1-8B-Instruct
--dtype auto
--max-model-len 8192
--gpu-memory-utilization 0.90
--download-dir /models
--host 0.0.0.0
--port 8000
--api-key dev-key
ports:
- "8000:8000"
volumes:
- ./models:/models
deploy:
resources:
reservations:
devices:
- capabilities: ["gpu"]
💡 Pro tip: Use ./models:/models to cache downloads — the model only has to be pulled once, and future restarts are instant.
Smoke test with curl
Chat Completions:
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer dev-key" \
-d '{
"model":"meta-llama/Meta-Llama-3.1-8B-Instruct",
"messages":[{"role":"user","content":"In one sentence, explain vLLM like I am 5."}],
"temperature":0.2,
"stream":true
}'
You should see streamed chunks back.
Test with C# (HttpClient)
Because the API matches OpenAI’s, you can call it directly from .NET without extra SDKs:
using System.Net.Http;
using System.Net.Http.Headers;
using System.Text;
using System.Text.Json;
using System.Text.Json.Serialization;
var apiKey = "dev-key";
var baseUrl = "http://localhost:8000/v1";
var model = "meta-llama/Meta-Llama-3.1-8B-Instruct";
using var http = new HttpClient { Timeout = TimeSpan.FromMinutes(2) };
http.DefaultRequestHeaders.Authorization = new AuthenticationHeaderValue("Bearer", apiKey);
var payload = new
{
model,
messages = new[]
{
new { role = "system", content = "You are a concise assistant." },
new { role = "user", content = "Give me 3 bullet points on continuous batching." }
},
temperature = 0.0
};
var json = JsonSerializer.Serialize(payload);
using var content = new StringContent(json, Encoding.UTF8, "application/json");
var resp = await http.PostAsync($"{baseUrl}/chat/completions", content);
resp.EnsureSuccessStatusCode();
var body = await resp.Content.ReadAsStringAsync();
var options = new JsonSerializerOptions { PropertyNameCaseInsensitive = true };
var completion = JsonSerializer.Deserialize<ChatCompletionResponse>(body, options);
Console.WriteLine(completion?.Choices[0].Message.Content);
public record ChatCompletionResponse(
[property: JsonPropertyName("choices")] Choice[] Choices
);
public record Choice([property: JsonPropertyName("message")] ChatMessage Message);
public record ChatMessage([property: JsonPropertyName("content")] string Content);
Where vLLM shines: real examples
- High-fan-in chatbots (help desks, contact centers) → Keeps GPU busy under irregular load.
- RAG/search APIs with uneven prompt sizes → PagedAttention avoids memory blowups.
- Multi-tenant agent backends (n8n, orchestration) → High throughput under mixed workflows.
- Latency-sensitive UI features (autocomplete, coding assistants) → Snappier user experience.
- Compared to naive runtimes → Often delivers order-of-magnitude throughput gains.
Tuning cheatsheet
- Memory headroom:
--gpu-memory-utilization 0.85–0.95. - Context length: set
--max-model-lenonly as high as you need. - I/O: cache models on SSD.
- Security: use
--api-keyand front with TLS proxy.
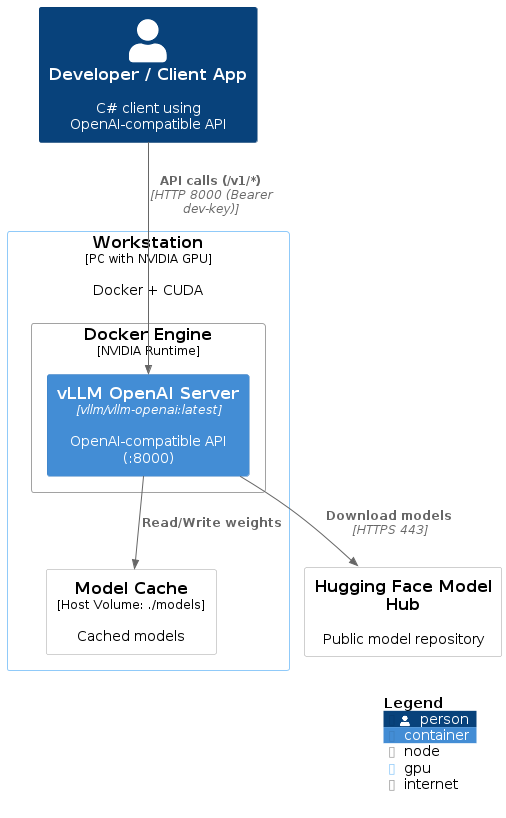
Deployment Diagram (PlantUML)
@startuml
!include <C4/C4_Deployment>
LAYOUT_WITH_LEGEND()
AddElementTag("gpu","GPU","#e3f2fd", $fontColor="black", $borderColor="#90caf9")
AddElementTag("internet","Internet","white", $fontColor="black", $borderColor="#9e9e9e")
Person(dev, "Developer / Client App", "C# client using OpenAI-compatible API")
Deployment_Node(ws, "Workstation", "PC with NVIDIA GPU", "Docker + CUDA", $tags="gpu") {
Deployment_Node(docker, "Docker Engine", "NVIDIA Runtime") {
Container(vllm, "vLLM OpenAI Server", "vllm/vllm-openai:latest", "OpenAI-compatible API (:8000)")
}
Deployment_Node(models, "Model Cache", "Host Volume: ./models", "Cached models")
}
System_Ext(hf, "Hugging Face Model Hub", "Public model repository", $tags="internet")
Rel(dev, vllm, "API calls (/v1/*)", "HTTP 8000 (Bearer dev-key)")
Rel(vllm, models, "Read/Write weights")
Rel(vllm, hf, "Download models", "HTTPS 443")
SHOW_LEGEND()
@enduml
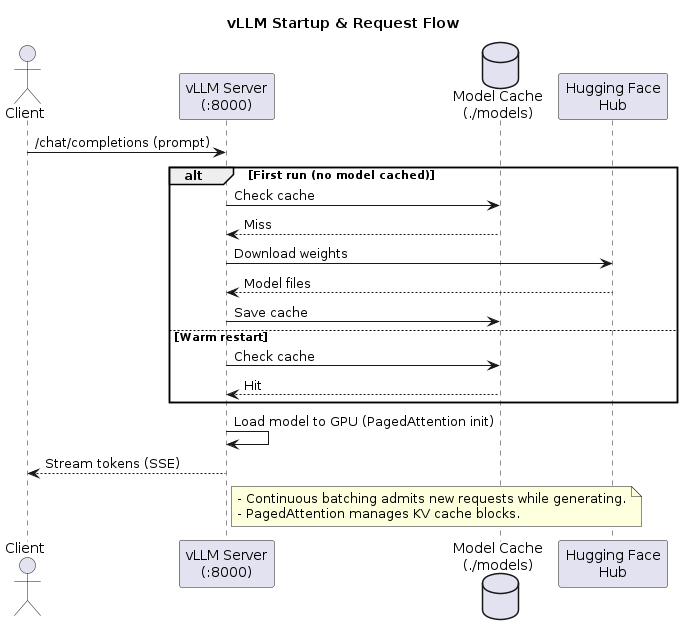
Sequence Diagram (PlantUML)
@startuml
title vLLM Startup & Request Flow
actor Client as C
participant "vLLM Server\n(:8000)" as V
database "Model Cache\n(./models)" as M
participant "Hugging Face\nHub" as HF
C -> V : /chat/completions (prompt)
alt First run (no model cached)
V -> M : Check cache
M --> V : Miss
V -> HF : Download weights
HF --> V : Model files
V -> M : Save cache
else Warm restart
V -> M : Check cache
M --> V : Hit
end
V -> V : Load model to GPU (PagedAttention init)
V --> C : Stream tokens (SSE)
note right of V
- Continuous batching admits new requests while generating.
- PagedAttention manages KV cache blocks.
end note
@enduml
Wrap-up
vLLM gives you an OpenAI-compatible API backed by continuous batching and paged KV caching — two battle-tested ideas that translate into higher throughput, lower latency, and better GPU utilization for real apps. With a tiny Compose file you can be production-ready in minutes, and you get to reuse your existing OpenAI clients with zero code changes.
Next time, integrating telegram chat box to our n8n workflow to search the podcasts!!! Read the previous post so you are up to date https://darthseldon.net/turning-hours-of-gamer-rants-into-searchable-gold-with-n8n-and-supabase/
Happy Coding!!!